|
Code (binary) |
(decimal unsigned) |
(decimal sign) |
|
|
A (capital Latin) | |||
|
B (capital Latin) | |||
|
a (small Latin) | |||
|
A (big Russian) Encoded ANSI | |||
|
A (big Russian) Encoded ASCII |
Similar code as shown above also matches an integer from 0 to 255 in unsigned format. Thus, each character is associated with an integer, also called a character code. A set of character codes is called code table or encoding .
For personal computers, the most common code tables are ANSI (American National Standard Institute) and ASCII (American Standard Code for Information Interchange). ANSI table is used in Windows, and ASCII was used in DOS. However, in these two tables the first 128 codes (from 0 to 127) match ; they differ only in the subsequent 128 codes used to store national (Russian) letters and “pseudographic” symbols.
In the tables given, the designation KS means "character code", and WITH- "symbol".
Standard part of the character table (ascii-ansi)
Some of the above symbols have special meanings. So, for example, a character with code 9 denotes a horizontal tab character, a character with code 10 is a line feed character, and a character with code 13 is a carriage return character.
Windows-1251 - character set and encoding, which is the standard 8-bit encoding for all Russian versions Microsoft Windows. This encoding is quite popular in Eastern European countries. Windows-1251 differs favorably from other 8-bit Cyrillic encodings (such as CP866, KOI8-R and ISO 8859-5) by the presence of almost all the characters used in traditional Russian typography for plain text (only the accent mark is missing). Cyrillic characters go to alphabetical order.
Windows-1251 also contains all the characters for languages close to Russian: Belarusian, Ukrainian, Serbian, Macedonian and Bulgarian.
In practice, this turned out to be enough for the Windows-1251 encoding to gain a foothold on the Internet until the spread of UTF-8.
| Dec | Hex | Symbol | Dec | Hex | Symbol | |
|---|---|---|---|---|---|---|
| 000 | 00 | NOP | 128 | 80 | Ђ | |
| 001 | 01 | SOH | 129 | 81 | Ѓ | |
| 002 | 02 | STX | 130 | 82 | ‚ | |
| 003 | 03 | ETX | 131 | 83 | ѓ | |
| 004 | 04 | EOT | 132 | 84 | „ | |
| 005 | 05 | ENQ | 133 | 85 | … | |
| 006 | 06 | ACK | 134 | 86 | † | |
| 007 | 07 | BEL | 135 | 87 | ‡ | |
| 008 | 08 | B.S. | 136 | 88 | € | |
| 009 | 09 | TAB | 137 | 89 | ‰ | |
| 010 | 0A | LF | 138 | 8A | Љ | |
| 011 | 0B | VT | 139 | 8B | ‹ | |
| 012 | 0C | FF | 140 | 8C | Њ | |
| 013 | 0D | CR | 141 | 8D | Ќ | |
| 014 | 0E | SO | 142 | 8E | Ћ | |
| 015 | 0F | S.I. | 143 | 8F | Џ | |
| 016 | 10 | DLE | 144 | 90 | ђ | |
| 017 | 11 | DC1 | 145 | 91 | ‘ | |
| 018 | 12 | DC2 | 146 | 92 | ’ | |
| 019 | 13 | DC3 | 147 | 93 | “ | |
| 020 | 14 | DC4 | 148 | 94 | ” | |
| 021 | 15 | N.A.K. | 149 | 95 | ||
| 022 | 16 | SYN | 150 | 96 | – | |
| 023 | 17 | ETB | 151 | 97 | — | |
| 024 | 18 | CAN | 152 | 98 | ||
| 025 | 19 | E.M. | 153 | 99 | ™ | |
| 026 | 1A | SUB | 154 | 9A | љ | |
| 027 | 1B | ESC | 155 | 9B | › | |
| 028 | 1C | FS | 156 | 9C | њ | |
| 029 | 1D | G.S. | 157 | 9D | ќ | |
| 030 | 1E | R.S. | 158 | 9E | ћ | |
| 031 | 1F | US | 159 | 9F | џ | |
| 032 | 20 | SP | 160 | A0 | ||
| 033 | 21 | ! | 161 | A1 | Ў | |
| 034 | 22 | " | 162 | A2 | ў | |
| 035 | 23 | # | 163 | A3 | Ћ | |
| 036 | 24 | $ | 164 | A4 | ¤ | |
| 037 | 25 | % | 165 | A5 | Ґ | |
| 038 | 26 | & | 166 | A6 | ¦ | |
| 039 | 27 | " | 167 | A7 | § | |
| 040 | 28 | ( | 168 | A8 | Yo | |
| 041 | 29 | ) | 169 | A9 | © | |
| 042 | 2A | * | 170 | A.A. | Є | |
| 043 | 2B | + | 171 | AB | « | |
| 044 | 2C | , | 172 | A.C. | ¬ | |
| 045 | 2D | - | 173 | AD | | |
| 046 | 2E | . | 174 | A.E. | ® | |
| 047 | 2F | / | 175 | A.F. | Ї | |
| 048 | 30 | 0 | 176 | B0 | ° | |
| 049 | 31 | 1 | 177 | B1 | ± | |
| 050 | 32 | 2 | 178 | B2 | І | |
| 051 | 33 | 3 | 179 | B3 | і | |
| 052 | 34 | 4 | 180 | B4 | ґ | |
| 053 | 35 | 5 | 181 | B5 | µ | |
| 054 | 36 | 6 | 182 | B6 | ¶ | |
| 055 | 37 | 7 | 183 | B7 | · | |
| 056 | 38 | 8 | 184 | B8 | e | |
| 057 | 39 | 9 | 185 | B9 | № | |
| 058 | 3A | : | 186 | B.A. | є | |
| 059 | 3B | ; | 187 | BB | » | |
| 060 | 3C | < | 188 | B.C. | ј | |
| 061 | 3D | = | 189 | BD | Ѕ | |
| 062 | 3E | > | 190 | BE | ѕ | |
| 063 | 3F | ? | 191 | B.F. | ї | |
| 064 | 40 | @ | 192 | C0 | A | |
| 065 | 41 | A | 193 | C1 | B | |
| 066 | 42 | B | 194 | C2 | IN | |
| 067 | 43 | C | 195 | C3 | G | |
| 068 | 44 | D | 196 | C4 | D | |
| 069 | 45 | E | 197 | C5 | E | |
| 070 | 46 | F | 198 | C6 | AND | |
| 071 | 47 | G | 199 | C7 | Z | |
| 072 | 48 | H | 200 | C8 | AND | |
| 073 | 49 | I | 201 | C9 | Y | |
| 074 | 4A | J | 202 | C.A. | TO | |
| 075 | 4B | K | 203 | C.B. | L | |
| 076 | 4C | L | 204 | CC | M | |
| 077 | 4D | M | 205 | CD | N | |
| 078 | 4E | N | 206 | C.E. | ABOUT | |
| 079 | 4F | O | 207 | CF | P | |
| 080 | 50 | P | 208 | D0 | R | |
| 081 | 51 | Q | 209 | D1 | WITH | |
| 082 | 52 | R | 210 | D2 | T | |
| 083 | 53 | S | 211 | D3 | U | |
| 084 | 54 | T | 212 | D4 | F | |
| 085 | 55 | U | 213 | D5 | X | |
| 086 | 56 | V | 214 | D6 | C | |
| 087 | 57 | W | 215 | D7 | H | |
| 088 | 58 | X | 216 | D8 | Sh | |
| 089 | 59 | Y | 217 | D9 | SCH | |
| 090 | 5A | Z | 218 | D.A. | Kommersant | |
| 091 | 5B | [ | 219 | D.B. | Y | |
| 092 | 5C | \ | 220 | DC | b | |
| 093 | 5D | ] | 221 | DD | E | |
| 094 | 5E | ^ | 222 | DE | YU | |
| 095 | 5F | _ | 223 | DF | I | |
| 096 | 60 | ` | 224 | E0 | A | |
| 097 | 61 | a | 225 | E1 | b | |
| 098 | 62 | b | 226 | E2 | V | |
| 099 | 63 | c | 227 | E3 | G | |
| 100 | 64 | d | 228 | E4 | d | |
| 101 | 65 | e | 229 | E5 | e | |
| 102 | 66 | f | 230 | E6 | and | |
| 103 | 67 | g | 231 | E7 | h | |
| 104 | 68 | h | 232 | E8 | And | |
| 105 | 69 | i | 233 | E9 | th | |
| 106 | 6A | j | 234 | E.A. | To | |
| 107 | 6B | k | 235 | E.B. | l | |
| 108 | 6C | l | 236 | E.C. | m | |
| 109 | 6D | m | 237 | ED | n | |
| 110 | 6E | n | 238 | E.E. | O | |
| 111 | 6F | o | 239 | E.F. | P | |
| 112 | 70 | p | 240 | F0 | R | |
| 113 | 71 | q | 241 | F1 | With | |
| 114 | 72 | r | 242 | F2 | T | |
| 115 | 73 | s | 243 | F3 | at | |
| 116 | 74 | t | 244 | F4 | f | |
| 117 | 75 | u | 245 | F5 | X | |
| 118 | 76 | v | 246 | F6 | ts | |
| 119 | 77 | w | 247 | F7 | h | |
| 120 | 78 | x | 248 | F8 | w | |
| 121 | 79 | y | 249 | F9 | sch | |
| 122 | 7A | z | 250 | F.A. | ъ | |
| 123 | 7B | { | 251 | FB | s | |
| 124 | 7C | | | 252 | F.C. | b | |
| 125 | 7D | } | 253 | FD | uh | |
| 126 | 7E | ~ | 254 | F.E. | Yu | |
| 127 | 7F | DEL | 255 | FF | I |
Description of special (control) characters
Originally, ASCII table control characters (range 00-31, plus 127) were designed to control hardware devices such as teletypewriters, punched tape data entry, etc.
Control characters (except horizontal tab, line feed, and carriage return) are not used in HTML documents.
| Code | Description |
|---|---|
| NUL, 00 | Null, empty |
| SOH, 01 | Start Of Heading |
| STX, 02 | Start of TeXt, beginning of the text |
| ETX, 03 | End of TeXt, end of text |
| EOT, 04 | End of Transmission, end of transmission |
| ENQ, 05 | Enquire. Please confirm |
| ACK, 06 | Acknowledgment. I confirm |
| BEL, 07 | Bell, call |
| BS, 08 | Backspace, go back one character |
| TAB, 09 | Tab, horizontal tab |
| LF, 0A | Line Feed, line feed Nowadays in most programming languages it is denoted as \n |
| VT, 0B | Vertical Tab, vertical tabulation |
| FF, 0C | Form Feed, page feed, new page |
| CR, 0D | Carriage Return Nowadays in most programming languages it is denoted as \r |
| SO,0E | Shift Out, change the color of the ink ribbon in the printing device |
| SI, 0F | Shift In, return the color of the ink ribbon in the printing device back |
| DLE, 10 | Data Link Escape, switching the channel to data transmission |
| DC1, 11 DC2, 12 DC3, 13 DC4, 14 | Device Control, device control symbols |
| NAK, 15 | Negative Acknowledgment, I do not confirm |
| SYN, 16 | Synchronization. Synchronization symbol |
| ETB, 17 | End of Text Block, end of the text block |
| CAN, 18 | Cancel, canceling previously transferred |
| EM, 19 | End of Medium |
| SUB, 1A | Substitute, substitute. Placed in place of a symbol whose meaning was lost or corrupted during transmission |
| ESC, 1B | Escape Control Sequence |
| FS, 1C | File Separator, file separator |
| GS, 1D | Group Separator |
| RS, 1E | Record Separator, record separator |
| US, 1F | Unit Separator |
| DEL, 7F | Delete, erase the last character. |
Before answering the question of what is ANSI Windows encoding, let us first answer another question: “What is encoding in general?”
Each computer, each system uses a certain set of characters, depending on the language used by the user, his professional competencies and personal preferences.
General definition of encoding
So, in Russian, 33 symbols are used to indicate letters, in English - 26. 10 digits are also used for counting (0; 1; 2; 3; 4; 5; 6; 7; 8; 9) and some special characters, minus , space, period, percentage and so on.
Each of these characters is assigned a serial number using a code table. For example, the letter "A" might be assigned the number 1; "Z" - 26 and so on.
Actually, the number representing the character as an integer is considered the character code, and the encoding is, accordingly, a set of characters in such a table.
Rich variety of code tables
On this moment There are quite a large number of encodings and code tables used by different specialists: these are ASCII, developed in 1963 in America, and Windows-1251, which was recently popular thanks to Microsoft, KOI8-R and Guobiao - and many, many others, and the process of their appearance and death continues to this day.
Among this huge list, the so-called ANSI encoding stands out in particular.
The point is that in due time Microsoft company created a whole set of code pages:
All of them are collectively called ANSI encoding table, or ANSI code page.
Interesting fact: one of the first code tables was ASCII, created in 1963 by the American National Standards Institute, abbreviated as ANSI.
Among other things, this encoding also contains non-printable characters, the so-called “Escape Sequences”, or ESC, which are unique to all character tables and are often incompatible with each other. When used skillfully, however, they allowed you to hide and restore the cursor, move it from one position in the text to another, set tabs, erase part of the terminal window in which you were working, change the formatting of text on the screen and change the color (or even draw and serve sound signals!). In 1976, by the way, this was a pretty good help for programmers. By the way, a terminal is a device required for input and output of information. In those distant times, it was a monitor and keyboard connected to a computer (electronic computer).
Incorrect display of characters
Unfortunately, in the future, such a system caused numerous failures in the systems, displaying instead of the desired poems, news feeds or descriptions of loved ones computer games so-called krakozyabry - meaningless, unreadable character sets. These ubiquitous errors were caused by simply trying to display characters encoded in one code table using another.

Most often, we still encounter the consequences of incorrect reading of this encoding on the Internet, when our browser for some reason cannot accurately determine which of the Windows **** encodings is currently in use, due to the instructions of the web -a master of the general ANSI encoding or an initially incorrect encoding, for example, 1252 instead of 1521. Below is the exact encoding table.
Cyrillic ANSI encoding table, Windows-1251
Moreover, in 1986, ANSI was significantly expanded, thanks to Ian E. Davis, who wrote The Draw package, which allows you not only to use the basic, from our point of view, functions, but also to fully (or almost fully) draw!

Summing up
Thus, you can see that the ANSI encoding, in fact, although it was a rather controversial decision, retains its position.

Over time, with the help of enthusiasts, the ancient ANSI terminal even migrated to telephones!
1.8 Protection algorithms performed by BMRZ
1.8.1 Three-stage overcurrent protection (MTZ) against phase-to-phase faults with current control in two or three phases(Code ANSI ) 50 ). Possibility to select one of four dependent time-current characteristics. Possibility of performing directional MTZ(Code ANSI 67 ), MTZ with combined voltage starting ) (Code ANSI 51 V), with correction for positive sequence voltage, overcurrent protection for phantom voltage. Automatic input of MTZ acceleration whenever the switch is turned on. Two MTZ programs for settings and program keys.
1.8.2 Fast directional protection(Code ANSI 67 ) from all types of short circuits with blocking via a high-frequency channel or fiber-optic communication line on overhead lines that do not have phase-by-phase switch control.
1.8.3 Directional or non-directional protection against single-phase earth faults (OSF)(Code ANSI 64 ), acting on shutdown and/or signaling with two time delays. Registration of high-frequency components in the zero-sequence current. Two setting programs(Code ANSI 50 G/ N).
1.8.4 Protection against asymmetry and phase loss of the supply feeder (ZOF) ( Code ANSI 46 ).
1.8.5 Minimum voltage protection (MVP) ( Code ANSI 27 ).
1.8.6 Logical protection of 6-10 kV buses (LZSH) ( Code ANSI 68 ).
1.8.7 Long-range backup (DR) in case of failure of protection or switches.
1.8.8 Undervoltage protection (LOP) when the switch is turned on ( Code ANSI 27 ).
1.8.9 Overvoltage protection (OVP) ( Code ANSI 59 ).
1.8.10 Distance protection (DP)( Code ANSI 21 ).
1.8.11 Minimum current protection of electric motors (Min TZ) ( Code ANSI 37 ).
1.8.12 Zero sequence current protection (ZCP) ( Code ANSI 51 N).
1.8.13 Protection against open-phase mode (LPFR).
1.8.14 Transformer differential protection ( Code ANSI87T), including:
Differential current protection with braking (DZT);
Differential current cut-off (DTO).
1.8.15 Differential motor protection ( Code ANSI87M), including:
Differential current cut-off (DTO);
Differential protection with braking (DZT);
Differential phase cutoff (DPC).
1.8.16 Tire differential protection (TIP) ( Code ANSI87ВВ).
1.8.17 Power Loss Protection (PLP) ( Code ANSI 27 / 59 ).
1.8.18 Overload protection ( Code ANSI 49 ).
1.8.19 Voltage monitoring (voltage transformer circuits; on busbars or in a line)
(Code ANSI 27 / 59 ).
1.8.20 Voltage synchronism control ( Code ANSI 25 ).
1.8.21 Locked rotor protection(Code ANSI 48 )and delayed engine start (ZBR) ( Code ANSI 14 ).
1.8.22 Thermal model of the electric motor (TM) ( Code ANSI 49 ).
1.8.23 Reverse power protection ( Code ANSI 32 P) and/or reactive power ( Code ANSI 32 Q).
1.8.24 Protection of circuit breaker control electromagnets.
1.8.25 Control of spring winding.
1.8.26 Executing arc protection commands from external devices.
1.8.27 Executing gas protection commands from external devices ( Code ANSI 63 ).
1.8.28 Execution of SF6 gas pressure control commands from external devices.
1.9 Automation algorithms
1.9.1 Determination of power direction (POD) ( Code ANSI67 / 50 / 51R) for directional MT or
for automatic switching between MTZ and OZZ programs.
1.9.2 Double or single automatic reclosing (AR) ( Code ANSI 79 ).
1.9.3 Redundancy in case of circuit breaker failure (breaker failure) ( Code ANSI 50 B.F.).
1.9.4 Automatic switching on reserve (AVR).
1.9.5 Determination of the location of damage (WMD).
1.9.6 Execution of automatic frequency shedding (AFS) and automatic restart commands
frequency (NAF) from external device frequency unloading.
1.9.7 Automatic frequency shedding (AFS).
1.9.8 Limitation of the number of engine starts (EKP) ( Code ANSI 66 ).
1.9.10 Control of electric drives of transformer voltage regulation devices under load.
1.9.11 Control of short circuiter and separator.
1.10 Control algorithms
1.10.1 Turning off and turning on the circuit breaker external teams and buttons on the front panel.
1.10.2 Online input/output of protection and automation functions based on external signals.
1.10.3 Remote change of settings.
Reg.ru: domains and hosting
The largest registrar and hosting provider in Russia.
More than 2 million domain names in service.
Promotion, domain mail, business solutions.
More than 700 thousand customers around the world have already made their choice.
*Mouse over to pause scrolling.
Back forward
Encodings: useful information and a brief retrospective
This article I decided to write how short review regarding the issue of encodings.
We will figure out what encoding is in general and touch a little on the history of how they appeared in principle.
We will talk about some of their features and also consider points that allow us to work with encodings more consciously and avoid the appearance of so-called krakozyabrov, i.e. unreadable characters.
So, let's go...
What is encoding?
To put it simply, encoding- this is a table of mappings of characters that we can see on the screen to certain numeric codes.
Those. Each character that we enter from the keyboard or see on the monitor screen is encoded with a certain sequence of bits (zeros and ones). 8 bits, as you probably know, are equal to 1 byte of information, but more on that later.
The appearance of the characters themselves is determined by the font files that are installed on your computer. Therefore, the process of displaying text on the screen can be described as a constant comparison of sequences of zeros and ones to some specific characters that are part of the font.
The progenitor of all modern encodings can be considered ASCII.
This abbreviation stands for American Standard Code for Information Interchange(American standard character set for printable characters and some special codes).
This single-byte encoding, which initially contains only 128 characters: letters of the Latin alphabet, Arabic numerals, etc.

Later it was expanded (initially it did not use all 8 bits), so it became possible to use not 128, but 256 (2 to the 8th power) different characters that can be encoded in one byte of information.
This improvement made it possible to add to ASCII symbols of national languages, in addition to the already existing Latin alphabet.
There are many options for extended ASCII encoding due to the fact that there are also many languages in the world. I think that many of you have heard about such encoding as KOI8-R is also an extended ASCII encoding, designed to work with Russian language characters.
The next step in the development of encodings can be considered the emergence of the so-called ANSI encodings.
Essentially they were the same extended versions of ASCII, however, various pseudo-graphic elements were removed from them and typographic symbols were added for which there were previously not enough "free spaces".
An example of such ANSI encoding is the well-known Windows-1251. In addition to typographic symbols, this encoding also included letters from the alphabets of languages close to Russian (Ukrainian, Belarusian, Serbian, Macedonian and Bulgarian).
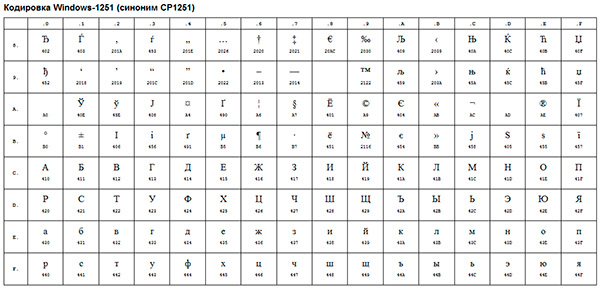
ANSI encoding is a collective name. In reality, the actual encoding when using ANSI will be determined by what is specified in your registry operating system Windows. In the case of Russian, this will be Windows-1251, however, for other languages it will be a different flavor of ANSI.
As you understand, a bunch of coding and the lack of a unified standard did not lead to any good, which was the reason for frequent meetings with the so-called krakozebras- an unreadable, meaningless set of characters.
The reason for their appearance is simple - it is attempting to display characters encoded with one character set using another character set.
In the context of web development, we may encounter bugs when, for example, Russian text is mistakenly saved in a different encoding than the one used on the server.
Of course, this is not the only case when we can get unreadable text - there are a lot of options here, especially if we consider that there is also a database in which information is also stored in a certain encoding, there is a connection mapping to the database, etc.
The emergence of all these problems served as an incentive to create something new. It had to be an encoding that could encode any language in the world (after all, with the help of single-byte encodings, no matter how hard you try, you cannot describe all the characters of, say, the Chinese language, where there are clearly more than 256 of them), any additional special characters and typography.
In a word, it was necessary to create a universal encoding that would solve the problem of crackers once and for all.
Unicode - Universal text encoding (UTF-32, UTF-16 and UTF-8)
The standard itself was proposed in 1991 by the non-profit organization "Unicode Consortium"(Unicode Consortium, Unicode Inc.), and the first result of his work was the creation of the encoding UTF-32.
By the way, the abbreviation itself UTF stands for Unicode Transformation Format(Unicode Conversion Format).
In this encoding, to encode one character it was supposed to use as many 32 bits, i.e. 4 bytes of information. If we compare this number with single-byte encodings, we will come to a simple conclusion: to encode 1 character in this universal encoding you need 4 times more bits, which makes the file 4 times heavier.
It is also obvious that the number of characters that could potentially be described using this encoding exceeds all reasonable limits and is technically limited to 2 to the 32nd power. It is clear that this was clearly overkill and wasteful in terms of the weight of the files, so this encoding did not gain distribution.
She was replaced by new development- UTF-16.
As is obvious from the name, in this encoding one character is encoded no longer 32 bits, but only 16(i.e. 2 bytes). Obviously, this makes any character twice as "light" as in UTF-32, but also twice as "heavier" than any character encoded using a single-byte encoding.
The number of characters available for encoding in UTF-16 is at least 2 to the 16th power, i.e. 65536 characters. Everything seems to be fine, and besides, the final code space in UTF-16 has been expanded to more than 1 million characters.
However, this encoding did not fully satisfy the needs of the developers. For example, if you write using exclusively Latin characters, then after switching from the extended version of the ASCII encoding to UTF-16, the weight of each file doubled.
As a result, another attempt was made to create something universal, and this something became the well-known UTF-8 encoding.
UTF-8- This multibyte variable-length encoding. Looking at the name, you might think, by analogy with UTF-32 and UTF-16, that 8 bits are used here to encode one character, but this is not the case. More precisely, not quite like that.
The point is that UTF-8 provides best compatibility with older systems that used 8-bit characters. To encode one character in UTF-8 is actually used from 1 to 4 bytes(hypothetically, up to 6 bytes are possible).
In UTF-8, all Latin characters are encoded in 8 bits, just like in ASCII.. In other words, the basic part of the ASCII encoding (128 characters) has moved to UTF-8, which allows you to “spend” only 1 byte on their representation, while maintaining the universality of the encoding, for the sake of which everything was started.
So, if the first 128 characters are encoded with 1 byte, then all other characters are encoded with 2 bytes or more. In particular, each Cyrillic character is encoded in exactly 2 bytes.
Thus, we have obtained a universal encoding that allows us to cover all possible characters that need to be displayed, without unnecessarily making the files heavier.
With BOM or without BOM?
If you have worked with text editors(code editors), for example Notepad++, phpDesigner, rapid PHP etc., then you probably noticed that when specifying the encoding in which the page will be created, you can usually choose 3 options:
ANSI
- UTF-8
- UTF-8 without BOM

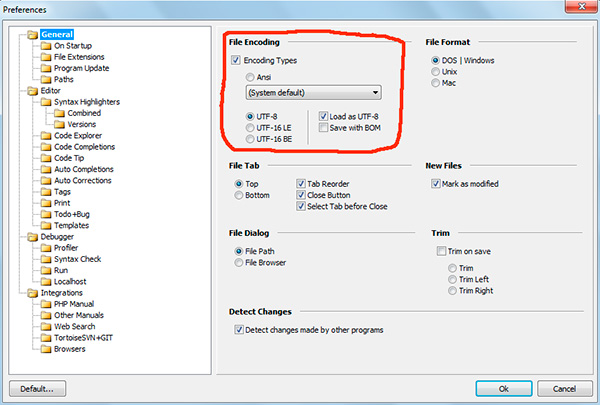

I’ll say right away that you should always choose the last option - UTF-8 without BOM.
So, what is BOM and why don't we need it?
BOM stands for Byte Order Mark. This is a special Unicode character used to indicate byte order. text file. According to the specification, its use is not mandatory, but if BOM is used, it must be set at the beginning of the text file.
We will not go into details of the work BOM. For us, the main conclusion is the following: using this service character together with UTF-8 prevents programs from reading the encoding normally, resulting in errors in the scripts.




